Another Blog Post About The CAP Theorem

I know there are a lot of blog posts talking about the CAP Theorem all over the web. I'm writing another one for two reasons:
I want to make it more visual. Rather than just write a bunch of words about it, I want to put some cool visualizations. That's, in my opinion, the best way to learn.
I want to write it down to help me to internalize this concept. I'm eager to try this "learn in public" thing.
First things first, what the heck is CAP?
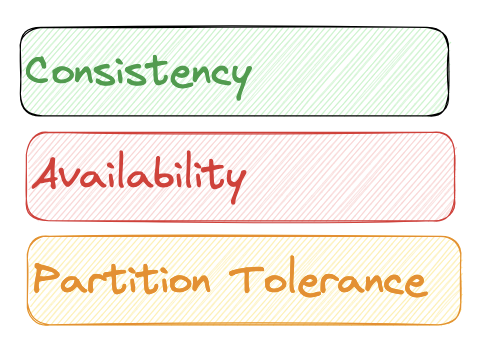
CAP stands for Consistency, Availability, and Partition Tolerance. Distributed systems gurus tell us that, in any distributed system scenario (databases, application servers, distributed file storage, etc.), we can only choose two and give up on one. Let's talk about each one of them before understanding why we can't have all three at once.
Consistency
Consistency means that in a distributed system, any query will have the same result - no matter to which node the query was sent. This is because the system is always in a 💫 consistent state 💫.
It's like two or more different people telling you the same thing when you ask about some gossip.

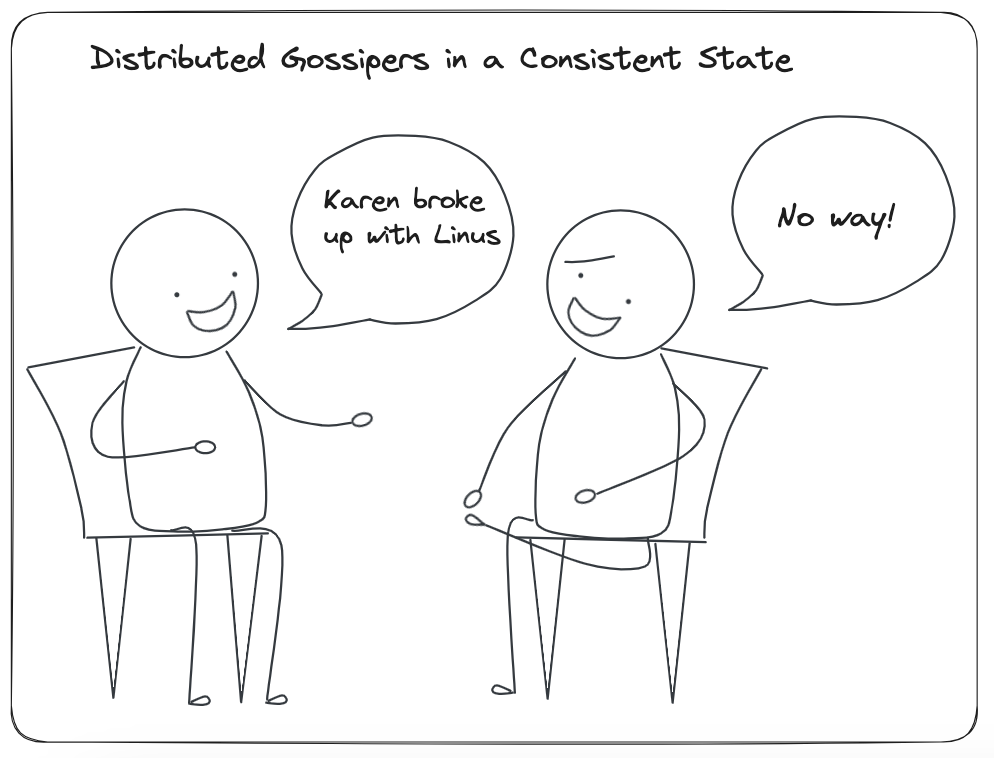
In the latter image, both gossipers know that Karen broke up with Linus. You can ask any of them, pretty sure they'll give you the same answer.
This is not much different from another distributed system, like databases for example:

No matter which of the three database replicas you send your query, they'll give you the same answer 😊. That's consistency.
Availability
Availability is pretty straightforward, you can tell what this means by its name: the system's components will be available when you need them. That means when you send a query, it'll get responded to because some node is available to handle your request.
Unavailability is like calling your friend when she's asleep. She's unavailable to answer your call.

A similar thing can happen when you send a request to an unavailable webserver or database.
In a scenario of availability, your request would be handled properly even if one of the servers was down. To ensure this, strategies like redundancy can be used.
A system has redundancy when more than one node is available to respond to requests. This way, when one node dies, the request can be routed to the remaining living nodes. Is like having a secretary to answer your calls while you're sleeping.
An example of redundancy in "computer terms" is when you have a load balancer in front of your web servers that redirects the requests to healthy servers, making the system available by avoiding unhealthy servers.
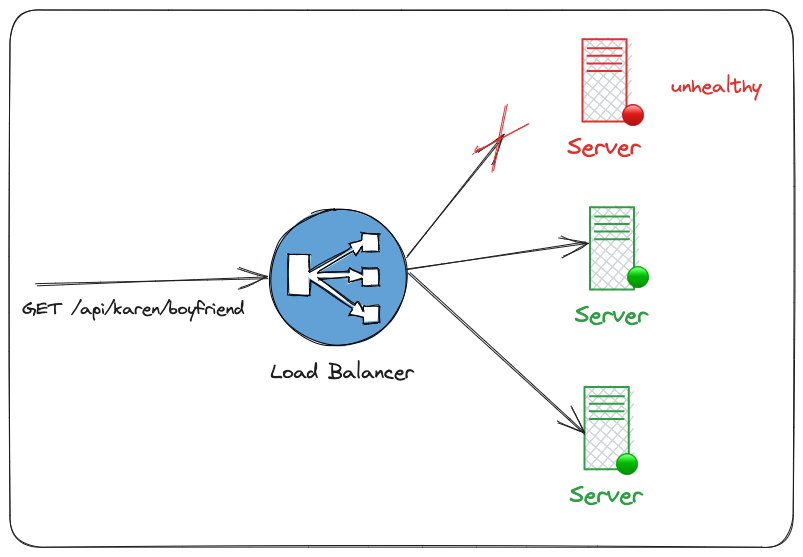
Partition Tolerance
Last but not least, let's talk about Partition Tolerance. This property means that the distributed system will remain functioning even in situations of network partitions. By network partitions, we mean any kind of connection break or delay between two nodes (both nodes are up and running, but can't communicate with each other or are facing communication lags).
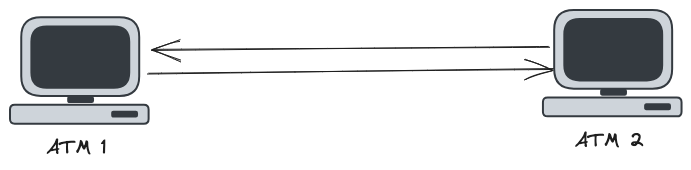
Let's dig into the classical two ATMs example to understand it deeply. Suppose that our distributed system is composed of two ATMs. These two ATMs communicate with each other directly, without an intermediate or a centralized server, like in the picture below.
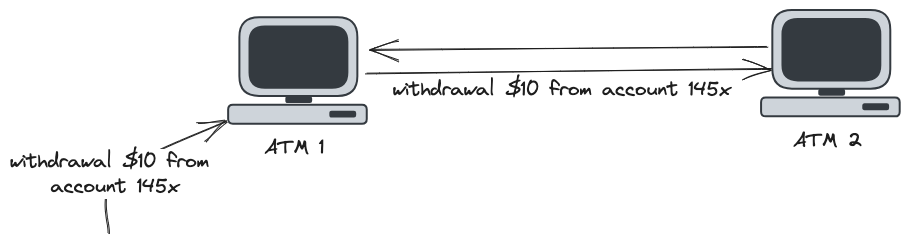
Consider that this system has only two possible operations: deposit and withdrawal. To keep the account balances in the same state, one ATM must communicate every operation to the other ATM. For example, if my account balance is $100 initially and I perform a withdrawal of $10 in ATM 1, ATM 1 must communicate the ATM 2 that I performed a withdrawal of $10 from my account. This way, by the end of the operation, both ATMs will have the most updated state of my account balance ($90).
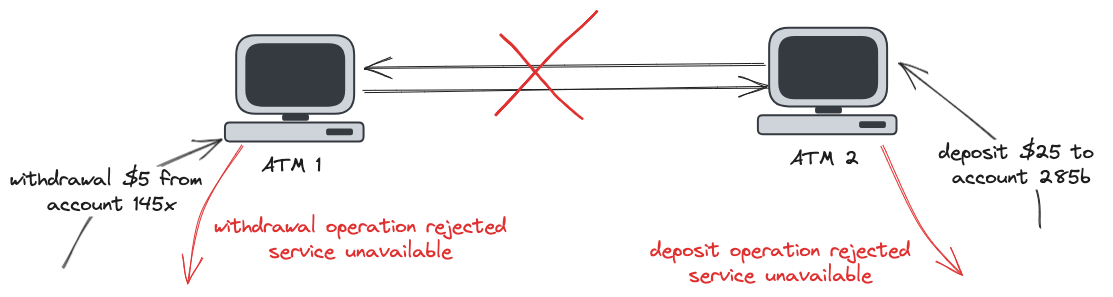
Now, imagine that a network partition happened and ATMs 1 and 2 are unable to communicate with each other. To keep the system running (partition tolerant), we need to choose between two options:
Option 1 - Give up on Availability, Choosing Consistency + Partition Tolerance (CP)
To keep the system consistent given the network partition, we need to stop the operations. Therefore, while the ATMs aren't able to communicate with each other, all deposits and withdrawals will be rejected, making the system unavailable.
Option 2 - Give up on Consistency, Choosing Availability + Partition Tolerance (AP)
Another option would be to accept all operations even with ATMs unable to communicate with each other. The problem with this approach is that this can lead the system to an inconsistent state.
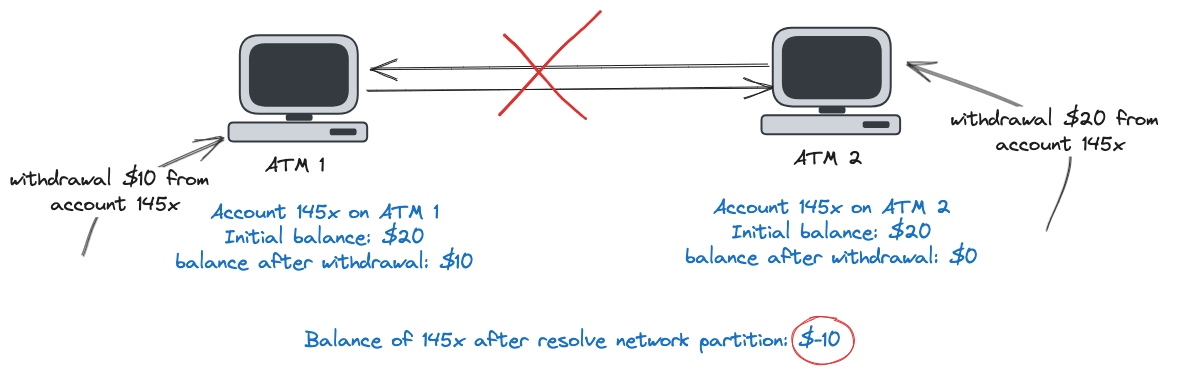
Imagine a situation where my initial account balance is $20, and this account balance is known by ATMs 1 and 2. Also, consider that this bank doesn't allow account balances to go negative. Suppose that I performed a withdrawal of $10 from my account on ATM 1, which is accepted since I have enough balance to do so. Then, I performed a withdrawal of $20 from my account on ATM 2, which was also accepted since $20 is equal to my current balance from ATM 2 point of view. When the network partition gets resolved and the ATMs communicate the operations that I did, I would have made a withdrawal of $30 from an account with a balance equal to $20, which should not be allowed.
And About Give up on Partition Tolerance, Choosing Consistency + Availability (CA)?
This is the least popular option and is a bit paradoxical. Some people even say that is not possible to give up on partition tolerance (and I agree with them). The only way to get consistency + availability is by guaranteeing no network partitions. But network partitions are always possible in distributed systems, by definition. Therefore, only non-distributed systems can achieve consistency + availability combo.
Further Reading
For more information about the CAP Theorem, take a look at these links:
